概述
tRPC 是一套由腾讯开源的高性能、跨多种编程语言、插件化的 RPC 框架。tRPC-Go 是框架在 Golang 编程语言下的官方实现。
本文剖析 tRPC-Go 框架的核心实现原理,并非 tRPC-Go 框架快速入门教程,所以不会有框架使用方法方面的介绍。
本文假设的读者是已经有一定的 tRPC-Go 框架使用经验或对 tRPC-Go 框架设计有基本了解的同学,我希望这篇文章能对想要更深入了解框架原理的同学提供有效的帮助。
通过阅读本文,你将可以:
- 熟悉 tRPC-Go 框架核心模块设计原理
- 以框架的核心流程为脉络自行延伸了解其他重要模块实现原理
注意:本文写作时,对应的 tRPC-go 框架版本是 v0.12.0。
tRPC-Go 架构速览
在一头扎进 tRPC-Go 核心组件的设计原理之前,我们先看看 tRPC-Go 框架的整体架构设计,这个架构图大家可以从 tRPC-Go 框架的官方文档中查到。
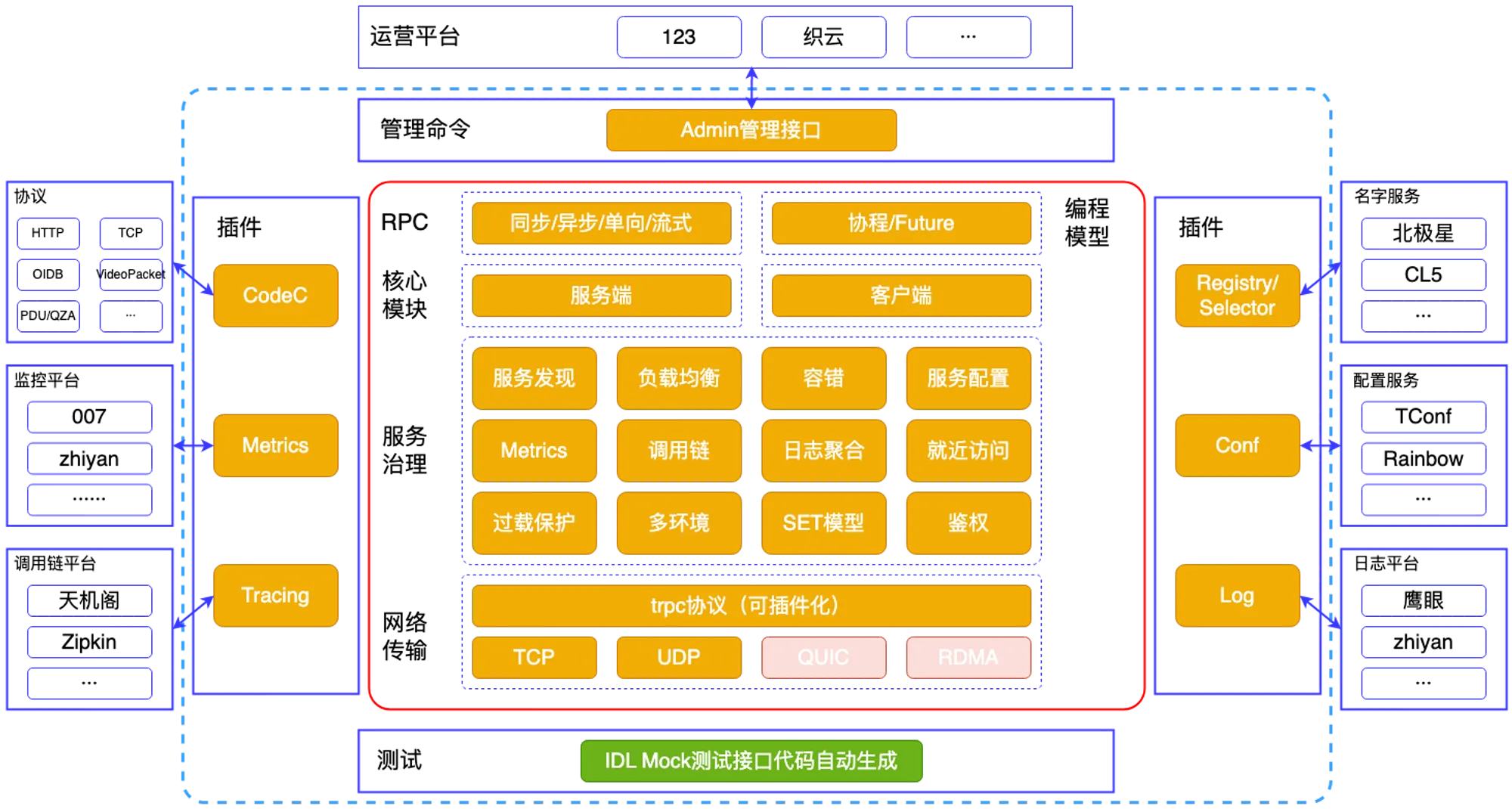
tRPC-Go 框架的最大设计亮点是清晰的组件划分以及高度的灵活性、可扩展性。
组件划分方面,框架在设计中考虑到了微服务治理中的常见问题,包括服务注册发现、分布式链路追踪以及服务可观测性等,对应到框架,其定义了 Metrics、Tracing、Selector、Conf 以及 Log 等组件;而 Codec 和 Transport 等组件则是 RPC 调用通信过程的标准化。
在灵活性和可扩展性的考量上,框架利用插件化设计思想,框架的核心组件均可以通过实现框架定义的各个接口来实现业务定制与扩展,我们在日常开发中,最容易接触到的就是各种各样的拦截器,这些都为 tRPC-Go 兼容腾讯内部已有各种协议与框架奠定了基础。
在这篇文章中,大家将会看到框架在 Codec 、Log 以及 Tracing 等方面的设计实现。
tRPC-Go 框架核心模块及应用详解
学习一个框架,最有效的方法就是先掌握它最基本的业务过程,其次再从各个流程分叉点延伸到各个角落,这样才不会在框架大量的代码中迷失了方向。对于一个网络应用框架而言,进程间的通信过程就是它最基本的业务过程。来一个非常熟悉的例子:一个 HTTP 请求从浏览器端发送到服务器端完成响应,再返回到浏览器端,发生了什么?当然不要怕,这个问题无需回答,放松。我只是为了提出我们今天的第一个问题:
一次 RPC 调用的核心过程是怎样的?需要经过哪些环节的处理?
一次 RPC 调用的核心过程
HTTP 客户端和服务器端双方想要通信,客户端需要先完成 HTTP 请求头和请求正文的组装,以及域名的解析,获得 IP 地址后,根据请求的 IP 和端口,交由传输层完成请求的传输;而服务器端在收到请求后,需要完成请求信息的结构化解析,然后执行相应的动作,最后同样通过传输层返回响应的头和正文给到浏览器端。
类比一下这个大致的过程,套到 RPC 框架的设计上,需要实现的过程其实是基本一致的,下面是我按照我个人理解,画出来的 RPC 调用过程的图示:
按照 tRPC 官方的叫法,发起请求的一方称之为主调方 caller,也可以称为上游;而响应请求的一方称之为被调方 callee,也可以称为下游。当然,你也可以按自己习惯管主调方叫客户端,管被调方叫服务端。我个人出于表达的习惯,我一般用主调方/被调方的叫法。
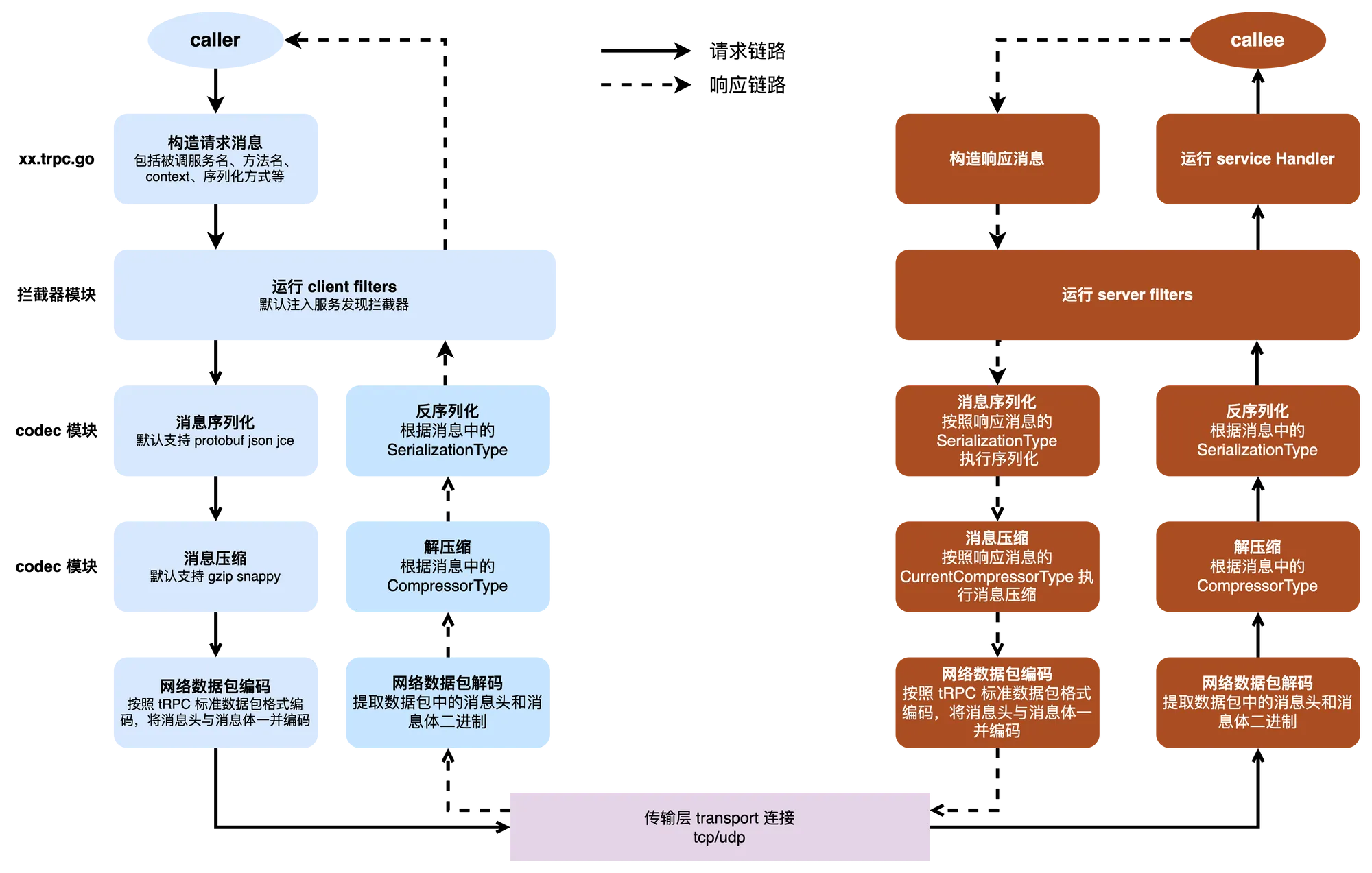
在这个图示的 tRPC-Go 请求响应过程中,实线表示主调方发送请求到被调方的过程;而虚线则是被调方处理完请求,返回结果到主调方的过程。与 HTTP 相似的,主调方需要:
- 通过 tRPC 框架生成的桩代码完成请求内容的内存结构化;
- 通过服务发现机制获取目标服务,也就是被调方的网络地址和端口号;
- 通过对消息依次进行序列化、压缩和编码,获得了二进制的消息,就可以通过传输层协议进行进程间的传输了。
当请求到达被调方之后,处理的过程和主调方刚好是相反的:
- 消息体需要按照 tRPC 的标准协议进行解码,分解出消息头与消息体,消息头用于框架做路由分发;
- 消息体经过解压缩和反序列化,使得被调方的应用层逻辑获得了内存中的结构化数据;
- 被调方的服务处理函数执行业务逻辑。
带着这个图,我们进入源码的世界(光看源码容易头晕和犯困,建议时不时翻回来看下上面的图,可以当成代码地图)。
首先,以一个 tRPC 调用为例,我们从主调方的桩代码出发:
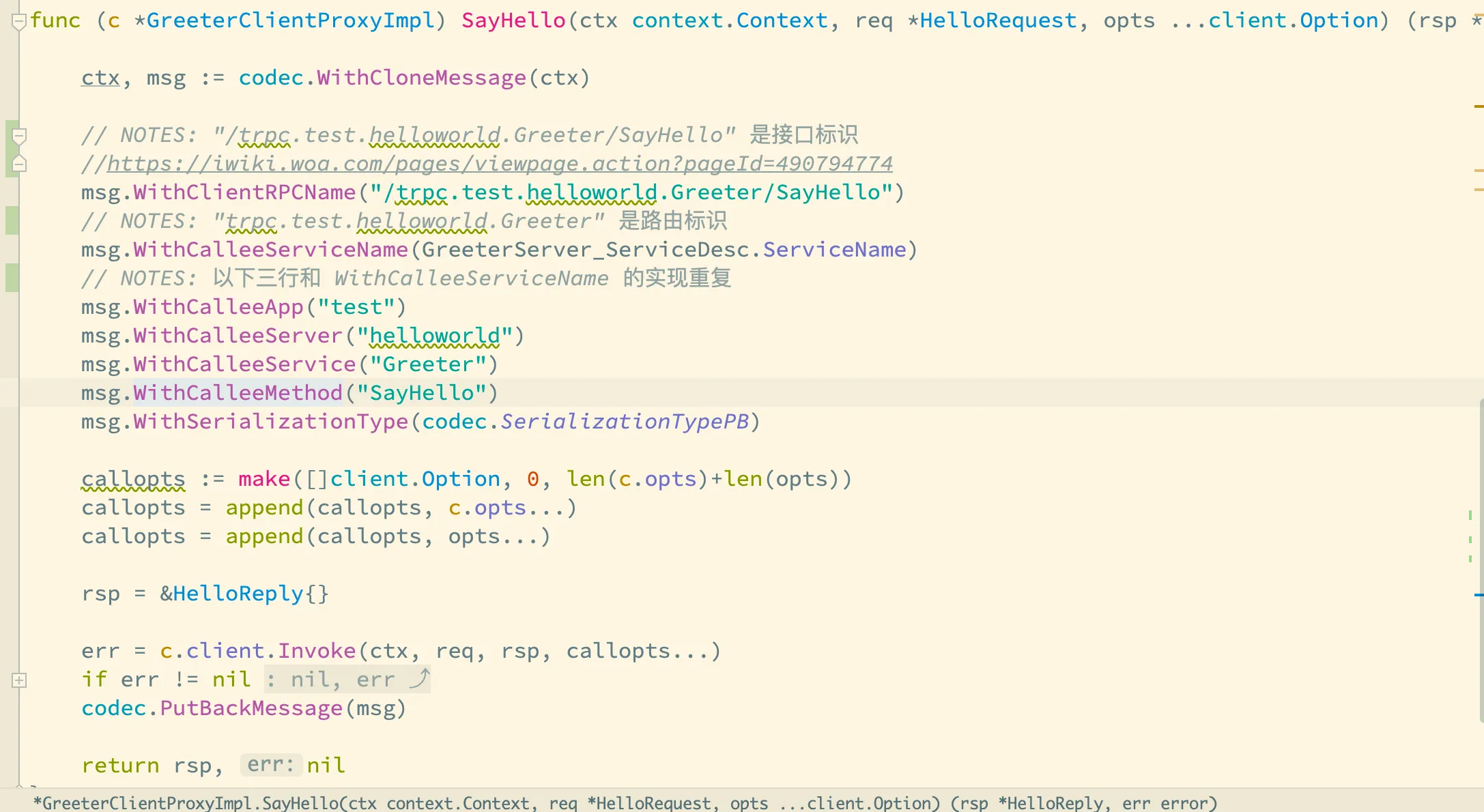
SayHello 是一个远程调用的桩代码,它会发起对被调方的 SayHello 方法的远程调用,桩代码里,主要是设置了消息的主被调双方信息,然后执行 c.client.Invoke 方法调用。我们可以看下 c.client 是何方神圣?在 SayHello 方法的代码上面,client 字段被赋值了 client.DefaultClient ,后者 client 是 tRPC-Go 框架源码里的一个包。我们看看这个包里的代码 client.DefaultClient……
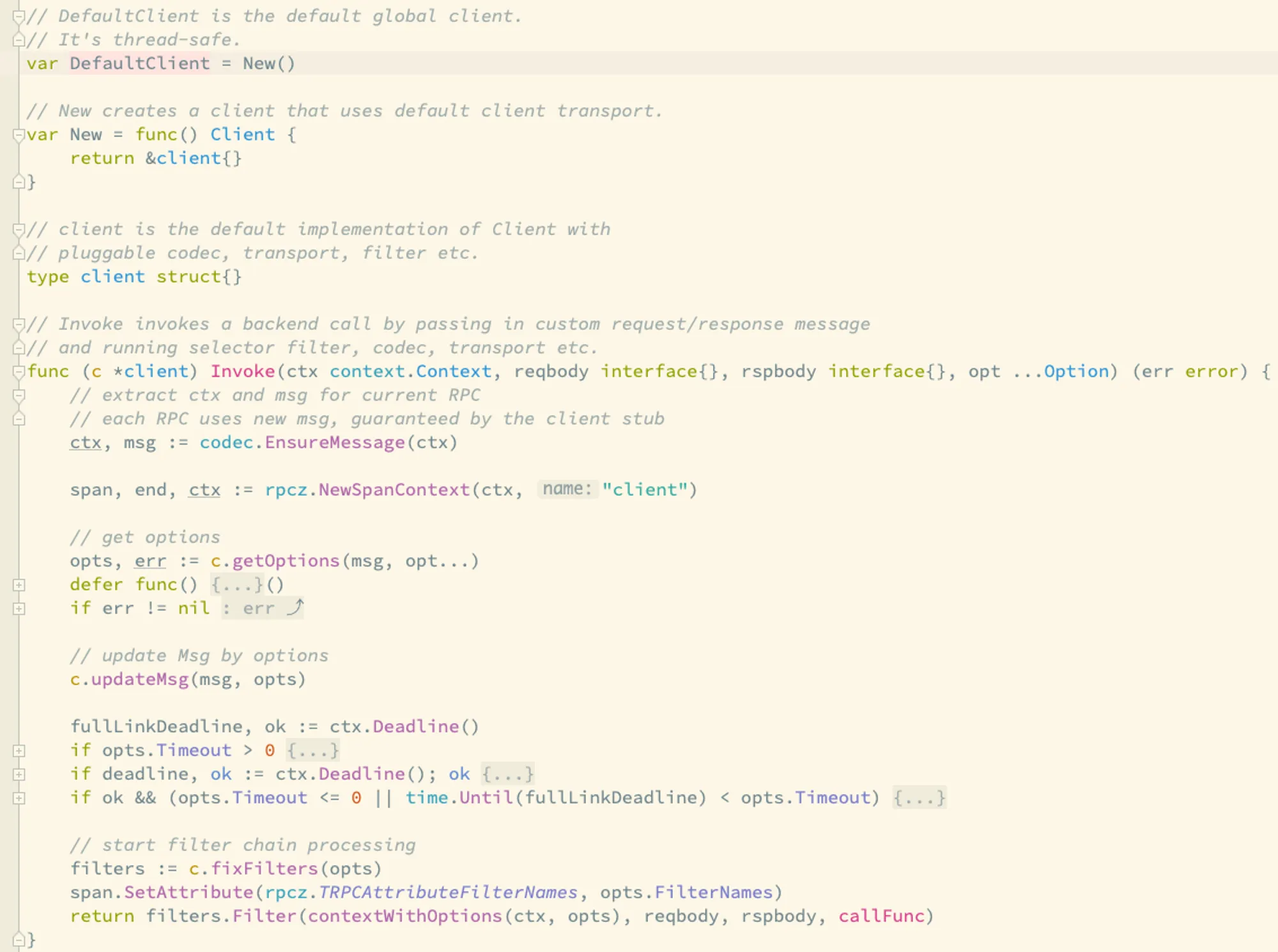
DefaultClient 是一个全局的变量,它是 client.client 类型的一个实例,这个实例由框架启动时初始化。找到了 DefaultClient,那我们就继续看它的 Invoke 方法,这是 RPC 调用的核心过程。
我们的视线可以快速定位到 filters := c.fixFilters(opts) 这一行,看起来是拦截器相关的逻辑,我们跟踪一下它的实现逻辑:

原来是在拦截器链的末尾加上了服务发现的拦截器。这就是前面图片里说的“默认注入服务发现拦截器”。跳出 fixFilters 这个方法,让我回到 Invoke 方法的下一行,也就是 filters.Filter(contextWIthOptions(ctx, opts), reqbody, resbody, callFunc)。我们直接看 callFunc 函数,它是整个 RPC 调用过程的核心逻辑:
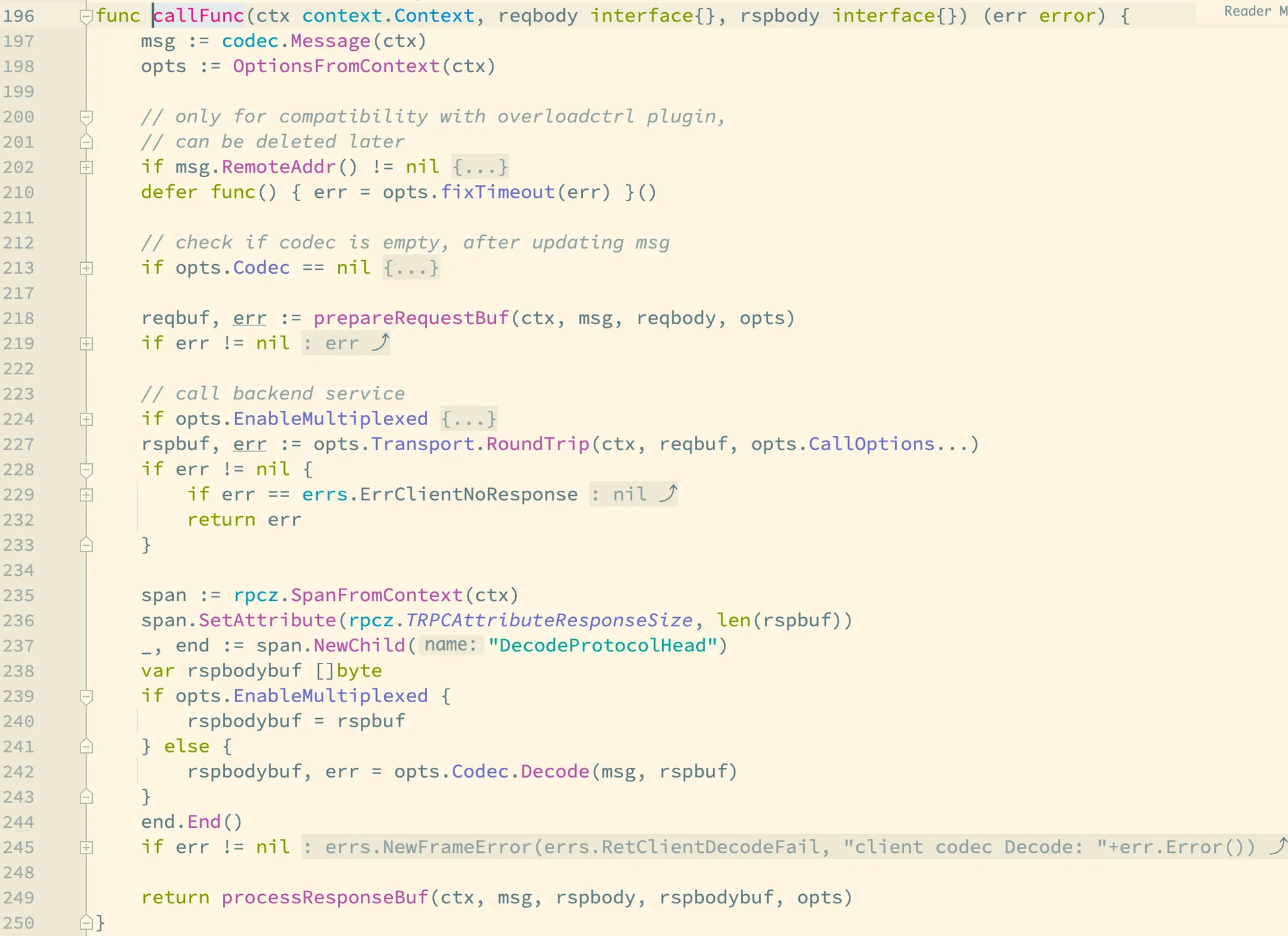
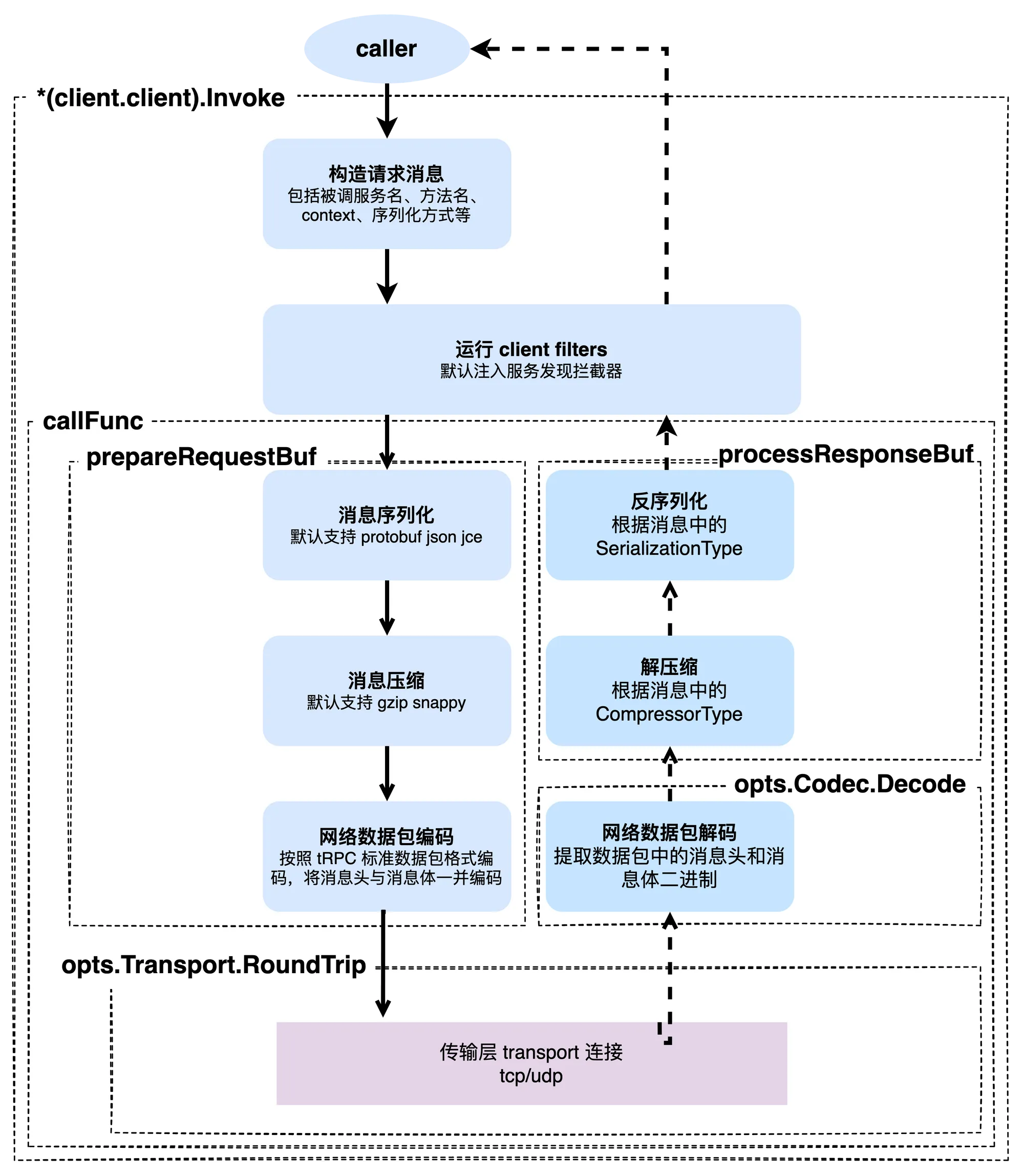
大致看一眼的话,有几个重要的函数调用,一个是 prepareRequestBuf,它完成整个请求的序列化和编码;然后是 opts.Transport.RoundTrip,完成传输层的调用;再接着是 opts.Codec.Decode(msg, rspbuf),完成响应消息的解码,最后是 processResponseBuf 函数,完成的是响应消息的反序列化等。我把这些函数或方法的调用过程和前面的流程图的主调方的处理过程做下关联图示:
我们继续往下看 prepareRequestBuf,它的实现很清晰,就是序列化、压缩,以及最后的编码:

回到 callFunc,我们这里略过部分函数,直接跳进来看 processResponseBuf:
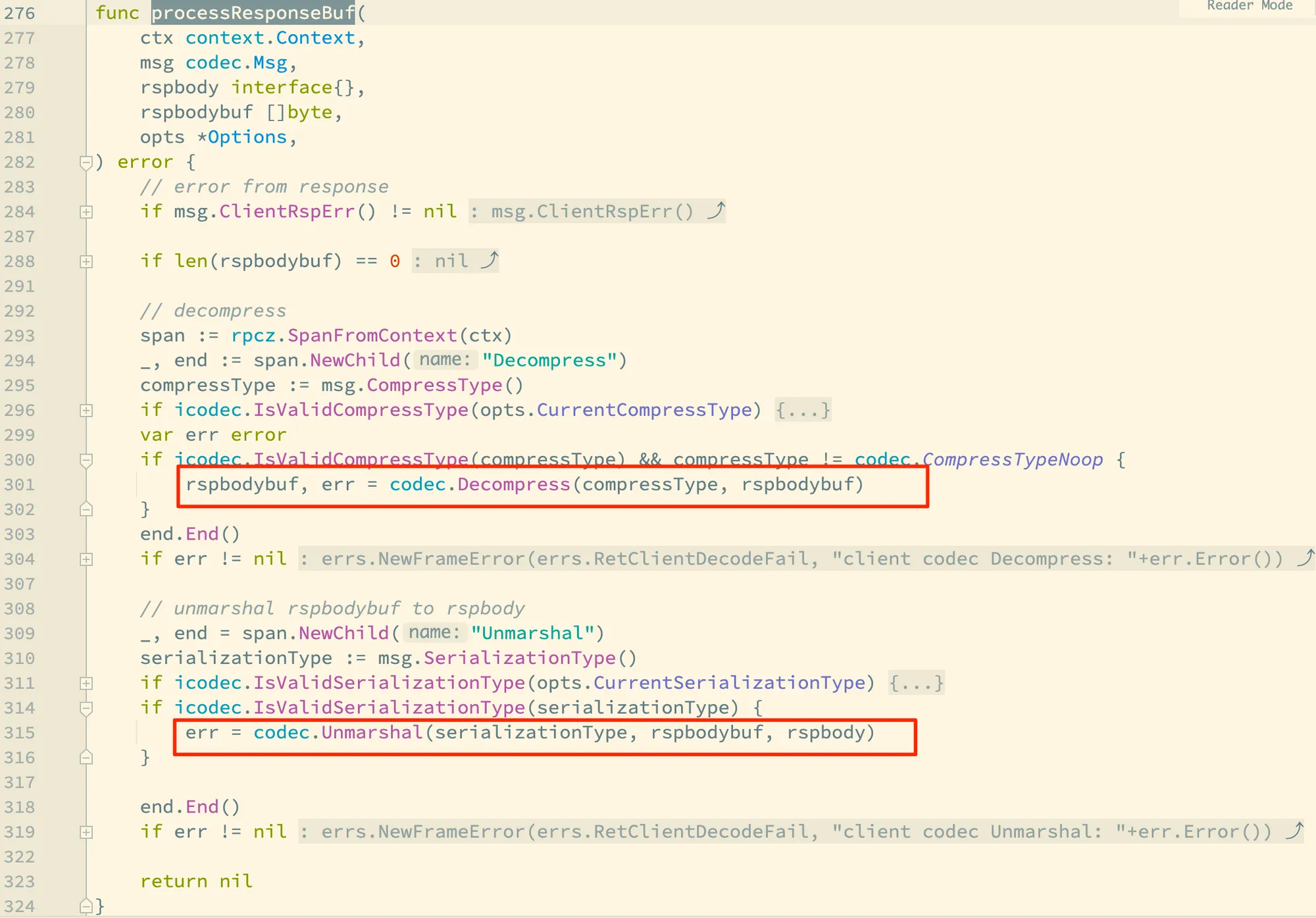
可以看到这里是先解压缩,然后做反序列化,所以和 prepareRequestBuf 刚好相反,不过有点不够对称的是,解码 Decode 没有包装到这里边,不然就是完美的对称了。
上面就是一个 RPC 调用的核心过程源码了,而被调方返回的过程和主调方请求的过程大体相同,我们就不赘述了,感兴趣的同学把这个当成练习,自己研究一波。
序列化与压缩
前面的内容是一个 RPC 请求的一个大致过程,现在开始我们用放大镜仔细解读关键的各个环节。让我们先聚焦到序列化和压缩这个环节。这是离框架用户更近,感知也更强的一个组件了。
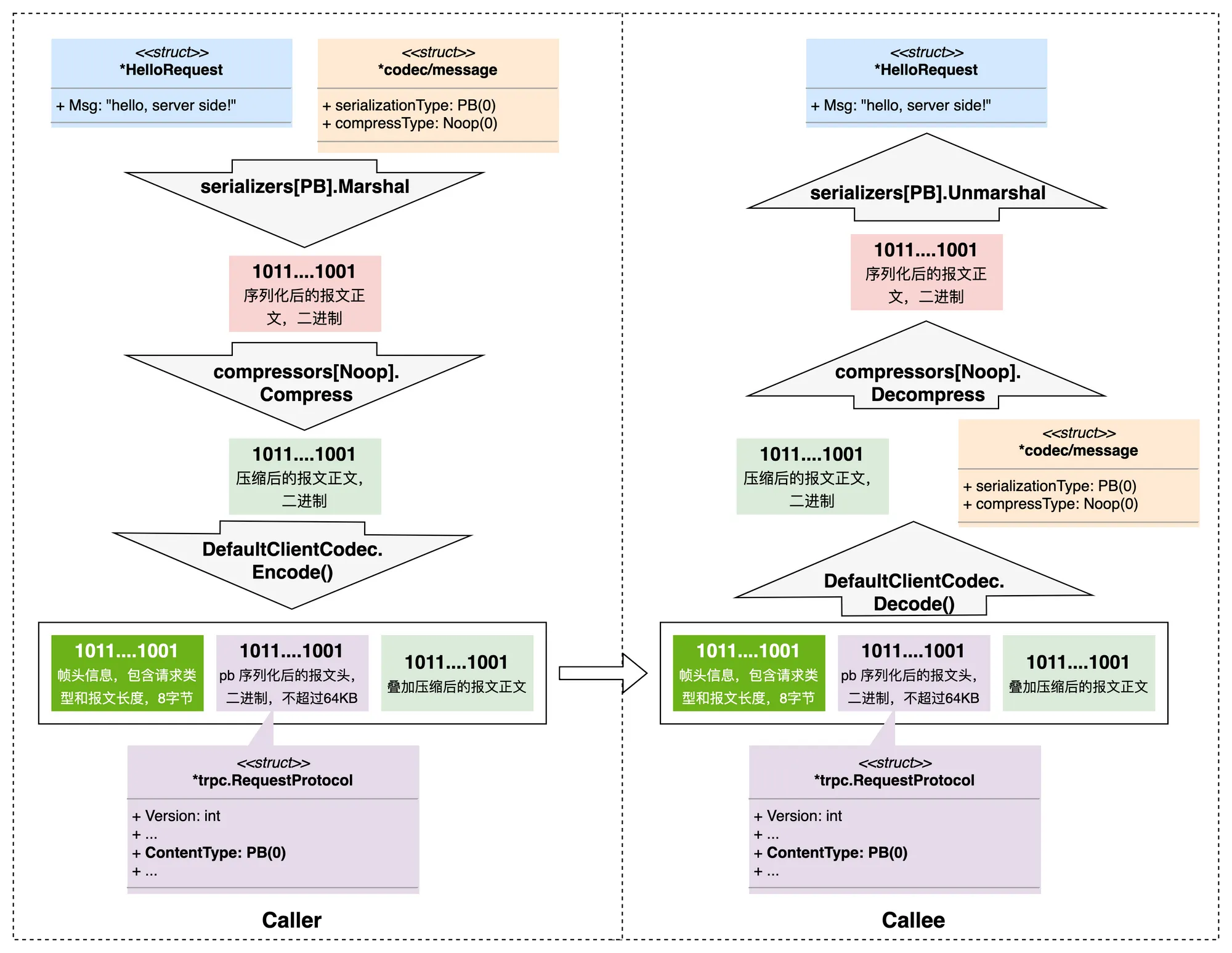
这个图是内存中的结构化数据序列化成二进制,再通过 tRPC 的网络协议进行编码后得到的整个二进制数据的示例过程,右边是被调方收到请求后,对请求进行解码以及反序列化的过程。
tRPC-Go 框架早期内置支持 pb、json 和 jce 三种序列化格式,以及 gzip、snappy 压缩格式,但是以现在的版本看的话,已经在框架内部又增加了更多的格式。tRPC 生成的桩代码里,默认会使用 pb 序列化格式,并且不使用任何压缩算法:
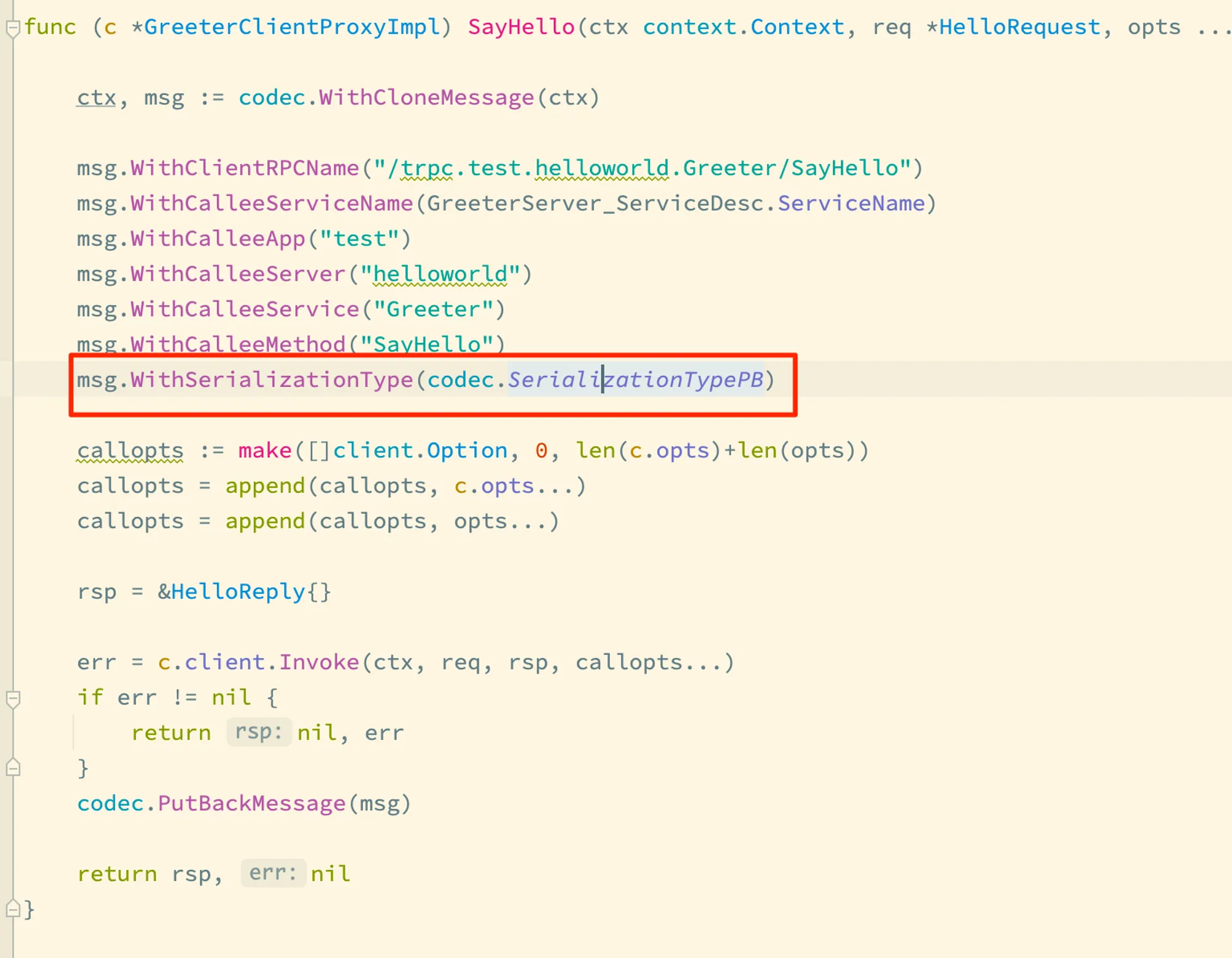
tRPC-Go 桩代码中默认使用 pb 序列化格式
要了解框架对于序列化和压缩的实现逻辑,我们需要在前面解读 tRPC-Go 请求过程源码中提到的 prepareRequestBuf 函数着眼:
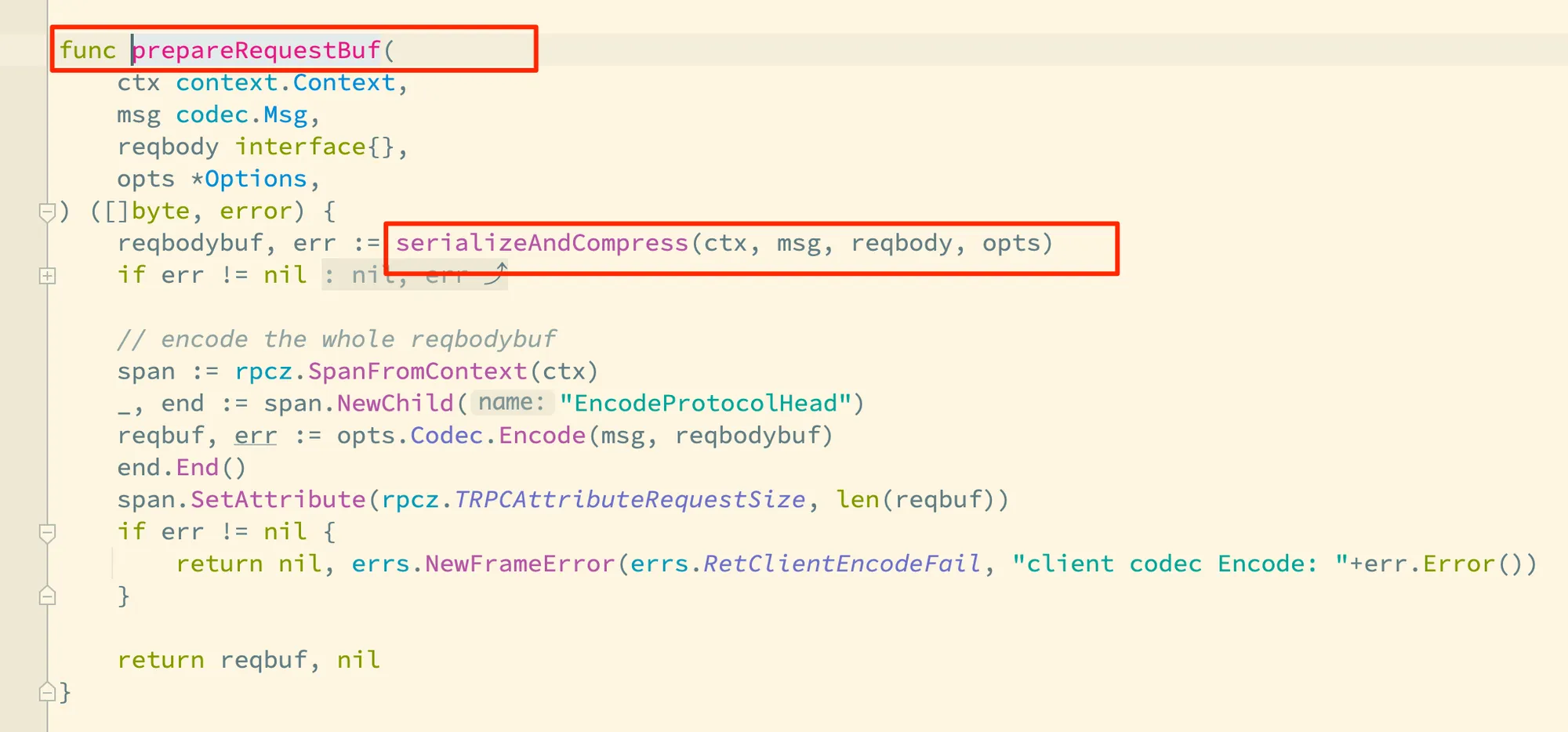
tRPC-Go 框架实现将序列化和压缩逻辑放在了一个独立的函数 serializeAndCompress 里,我们跟进去看下这个函数的实现:
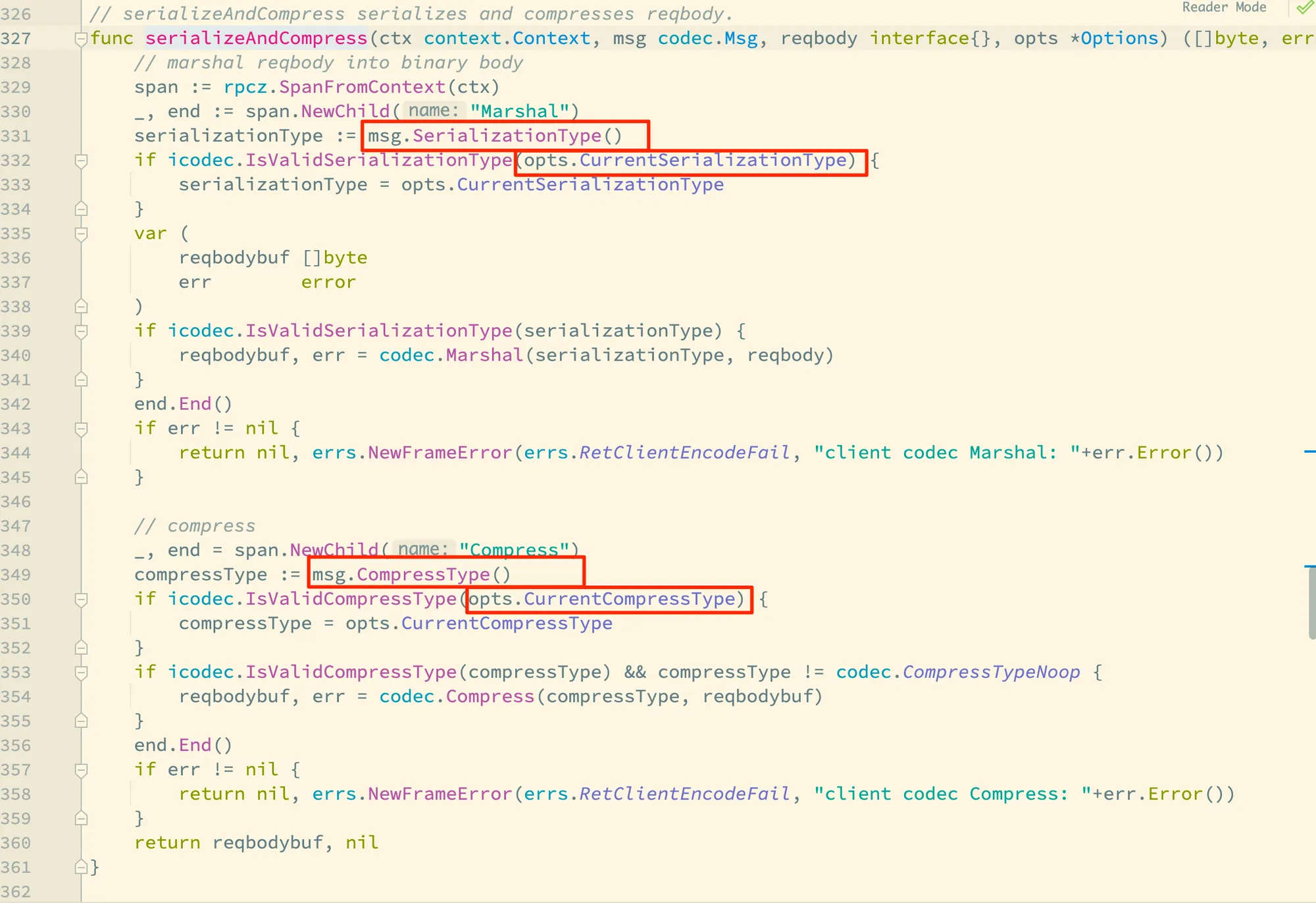
这里的:
msg.SerializationType()即为桩代码中msg.WithSerializationType(codec.SerializationTypePB)设置的序列化格式,即框架默认使用 PB 序列化;msg.CompressType()则为通过msg.WithCompressType(int)设置的压缩格式,但是这个在桩代码中没有体现,即框架默认不使用任何压缩格式。 不过这里还有一点有意思的是,但从框架这处源码来看,消息体携带的序列化格式或者压缩格式不合法时,框架却不会做任何错误返回,有可能在特定场景会导致难以发现的缺陷。后面还会讲到这个地方;opts参数则是提供了一种在运行时覆盖序列化格式以及压缩格式的机制。
我们看下 icodec.IsValidSerializationType() 这个函数是怎么判断合法的序列化格式的:

这个函数判断逻辑是:只有枚举值大于等于 codec.SerializationTypePB 的序列化格式才是合法的格式。我们再看看内置的枚举值:
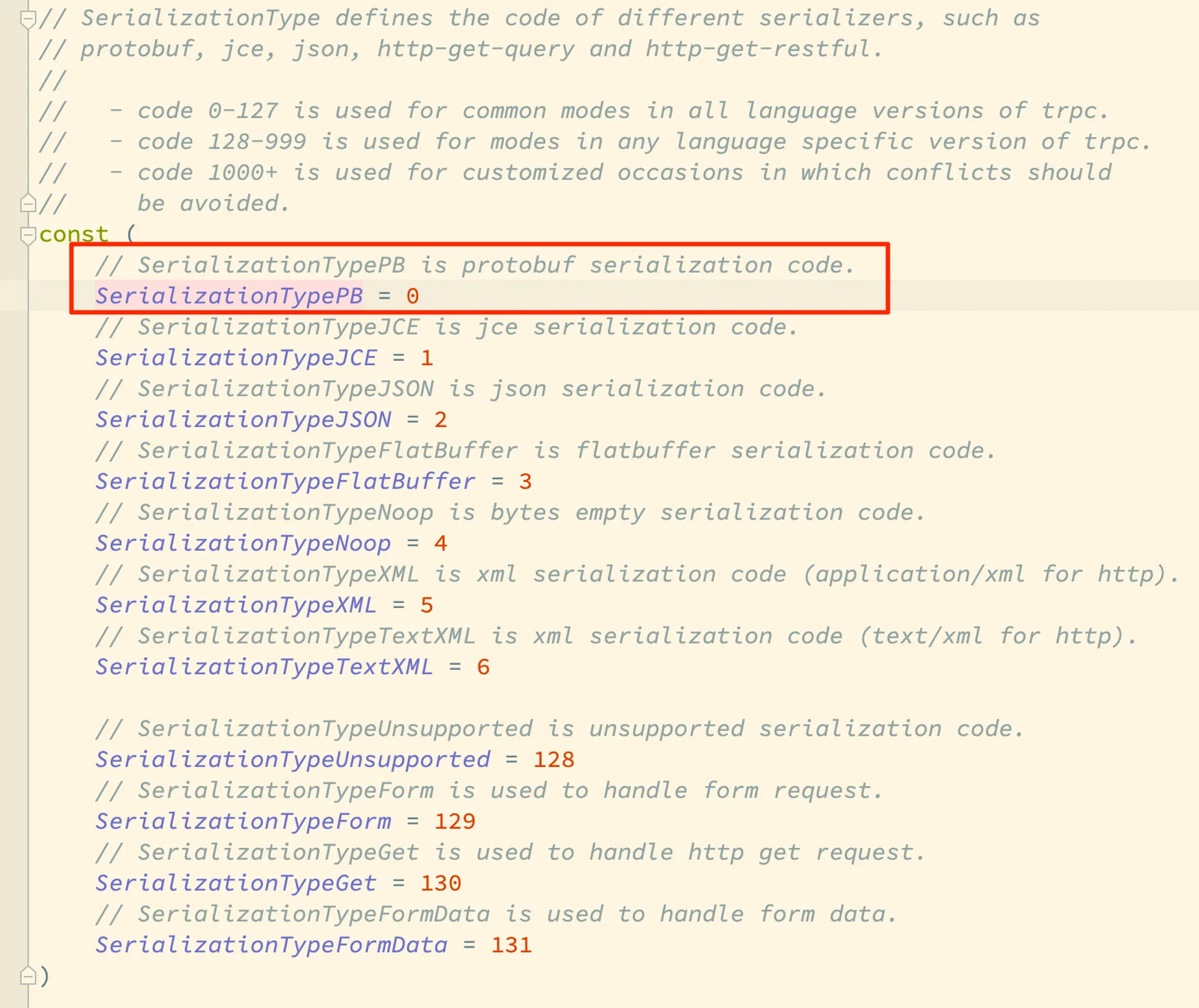
可以看到默认的 PB 格式就是 0,而注释中则约定了序列化格式枚举值的号段规则:
- 语言无关的序列化格式使用 0-127 序号,目前用到了7个号码;
- 与特定语言相关的序列化格式使用使用 128-999 的序号,这个号段目前定义了 4 个格式;
- 而业务自定义的序列化格式需要使用 1000 以上的枚举值。
回到 serializeAndCompress 这个函数体中的 codec.Marshal(serializationType, reqbody),这个函数主要是用来加载对应的序列化器,并且调用它的 Marshal 方法:

这里会看到它在这里最终处理了序列化格式不合法的场景的。再看到 GetSerializer 函数的实现,它从 serializers 全局变量中获取对应序列化器,而序列化器都需要在启动时通过 RegisterSerializer 函数注册上来,这也是自定义的序列化器必须在框架初始化时调用的函数。

以上就是主调在请求阶段关于序列化和压缩的相关逻辑。
消息编解码
序列化和压缩解决的是如何将消息体转换为二进制的问题,而编码步骤则完成消息头的编码以及完整的请求帧的编码,做好传输层二进制传输的准备。
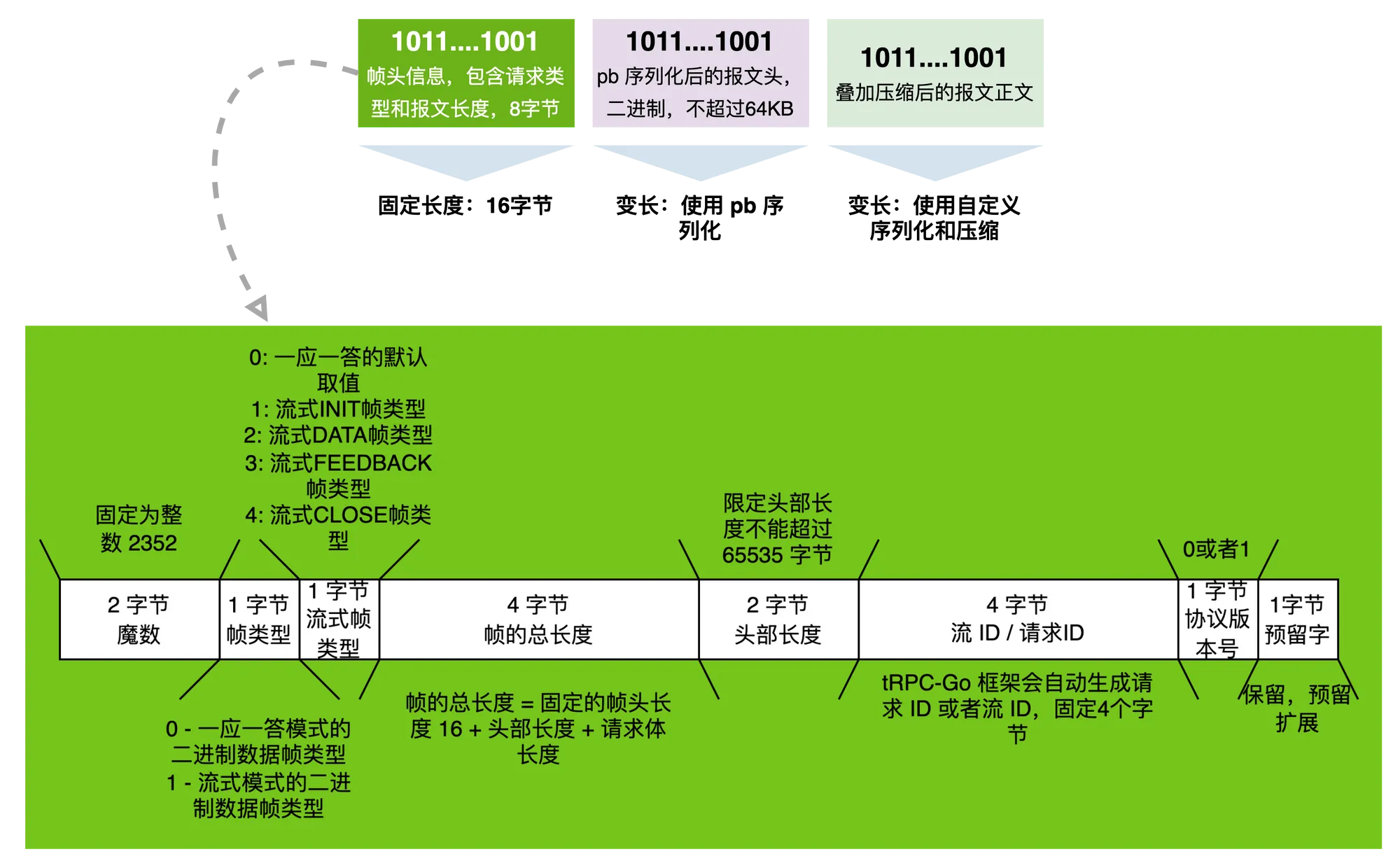
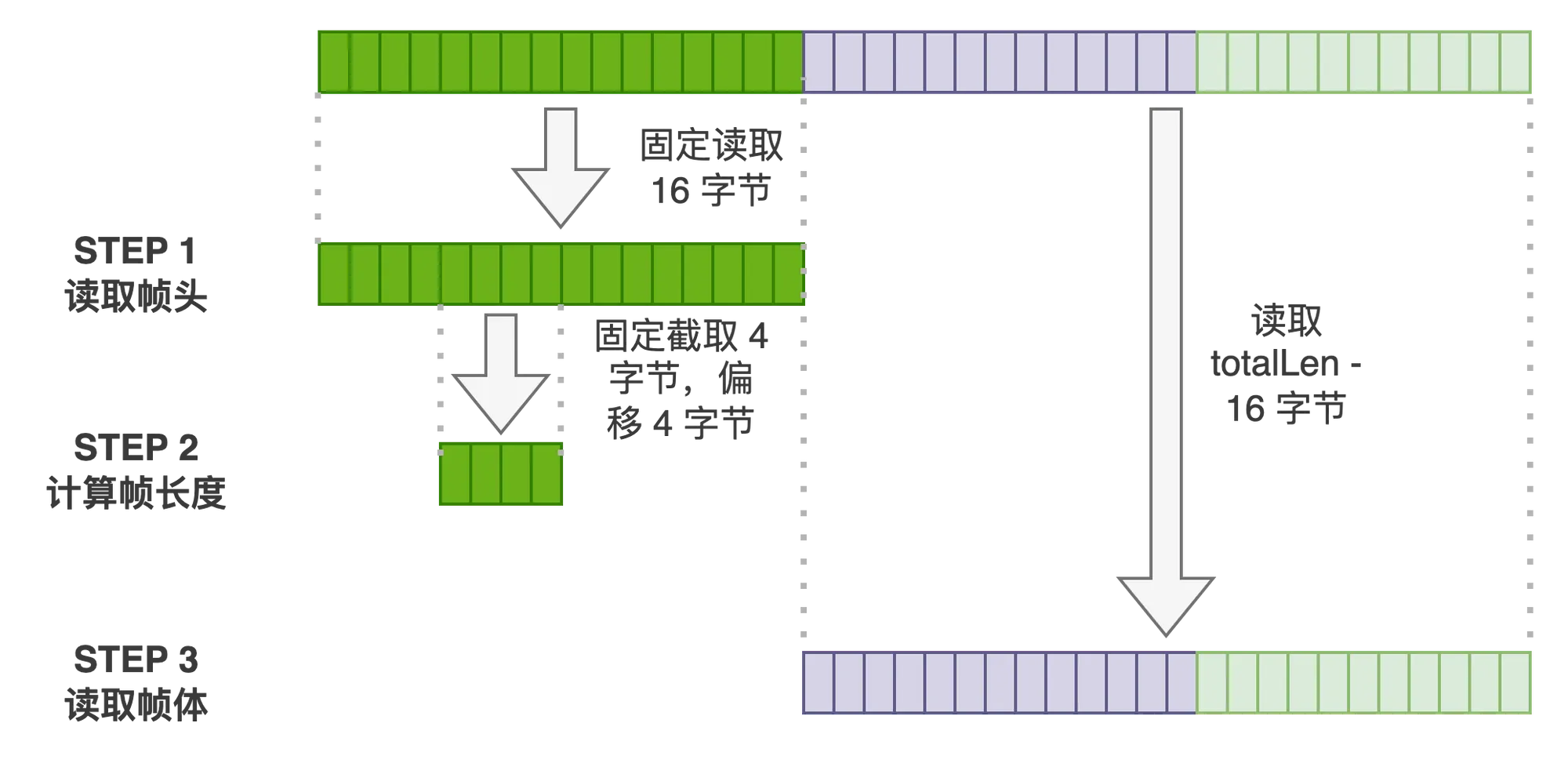
上面是一个 tRPC 网络协议封包格式的图示,一个 tRPC 帧包含帧头、报文头以及报文体三部分,帧头长度固定16个字节,报文头和报文体长度可变。我们在框架中设置的各种上下文信息,比如使用的序列化格式、压缩格式、主被调信息以及透传信息等,都会放在标准的报文头里,这部分强制使用 pb 协议序列化,而报文体的序列化和压缩方式,则是前面已经讲解过的部分。所以我们重点可以了解一下帧头的格式。
帧头开头是 2 个字节的魔数,在 tRPC 协议中固定是整数 2352。魔数的作用是在数据传输或文件读取的过程中,让接收方能够快速准确地识别数据格式和协议类型,以便正确地处理数据。如果魔数匹配失败,则可能导致数据解析错误或协议错误,甚至可能引发安全漏洞。所以魔数可以理解为是用来快速识别帧头以及确认帧正确性的快捷方式。
在魔数后面是 1 字节的帧类型,因为 tRPC 支持不同的请求响应模式,这里的帧类型用于区分具体模式,这篇文章里的讲解都只关注一问一答这种模式。
如果帧类型是 1,也就是流式模式,则第4个字节就会有意义,它表示流式模式中数据帧的具体类型。
接下来的第5-8个字节表示整个帧的长度,因为帧头本身占用了16个字节,所以报文和报文体加起来的最大长度允许为 2^32-16 个字节。
第9-10个字节表示帧头长度,也就是限定了 tRPC 协议下,报文头最大长度不超过 65535 个字节。
第11-14个字节表示请求 ID或者流 ID。
第15个字节表示当前报文使用的 tRPC 协议版本号,而第 16 个字节是保留字节,保留字节是一种扩展性的考虑,常见的网络协议中都会有类似的设计。
我们同样来解读一下代码,编码相关的逻辑入口同样是在框架的 client.prepareRequestBuf 函数体中,对应的函数调用是 opts.Codec.Encode(msg, reqbodybuf),而 trpc 协议对应的客户端编码器则是 trpc.DefaultClientCodec:
我们看下它的 Encode 方法的实现:
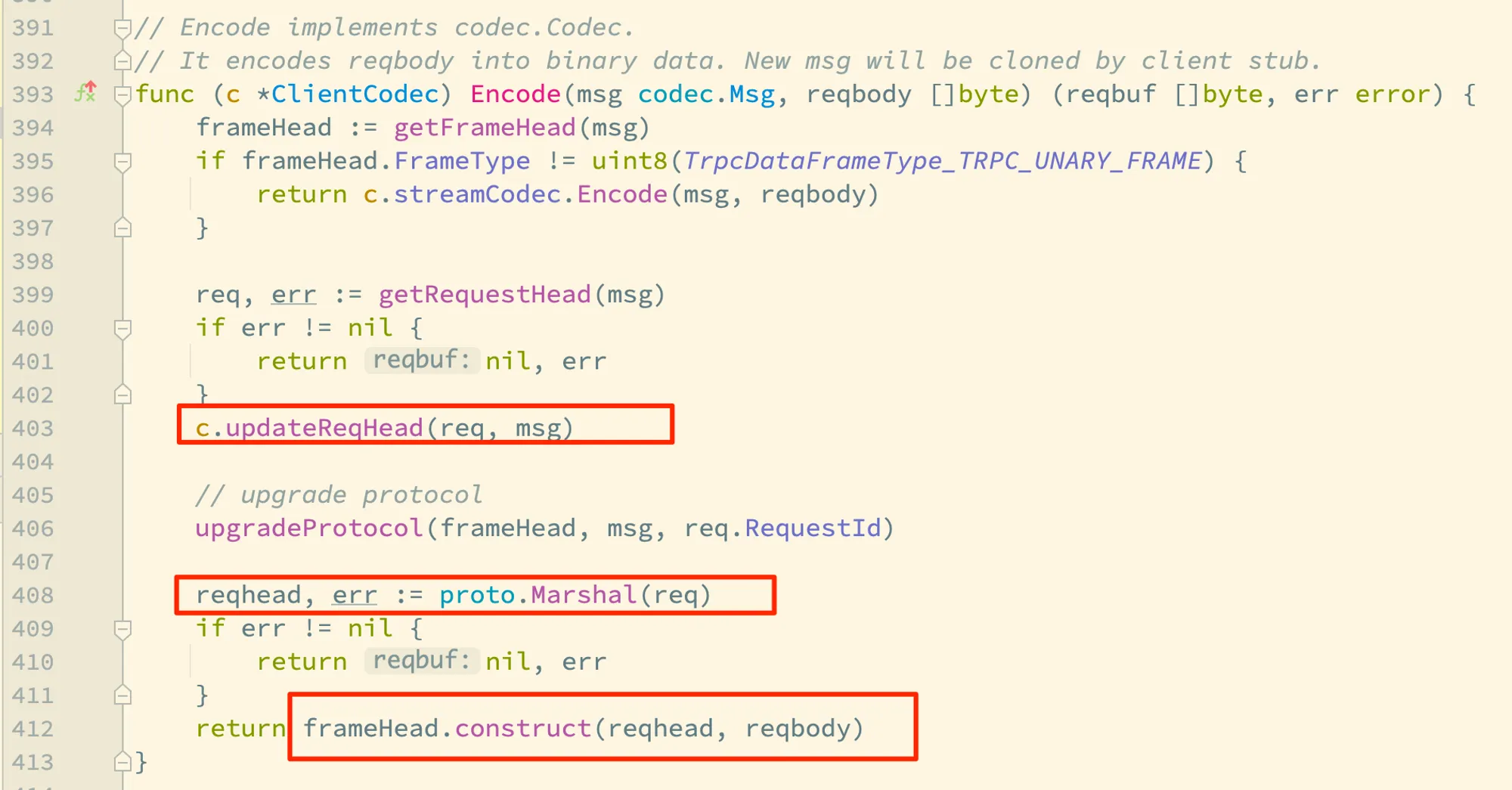
这里的 getRequestHead 和 c.updateReqHead 用于初始化消息体的数据结构 req ,具体的实现逻辑我们后面还会讲解,这里先聚焦在编码本身。
消息体 req 经过了 pb 协议的序列化,和经过了序列化和压缩的消息体 reqbody 一同传递给了 frameHead.construct 的调用,trpc.FrameHead 封装了协议帧的处理逻辑,我们看看它的 construct 方法:
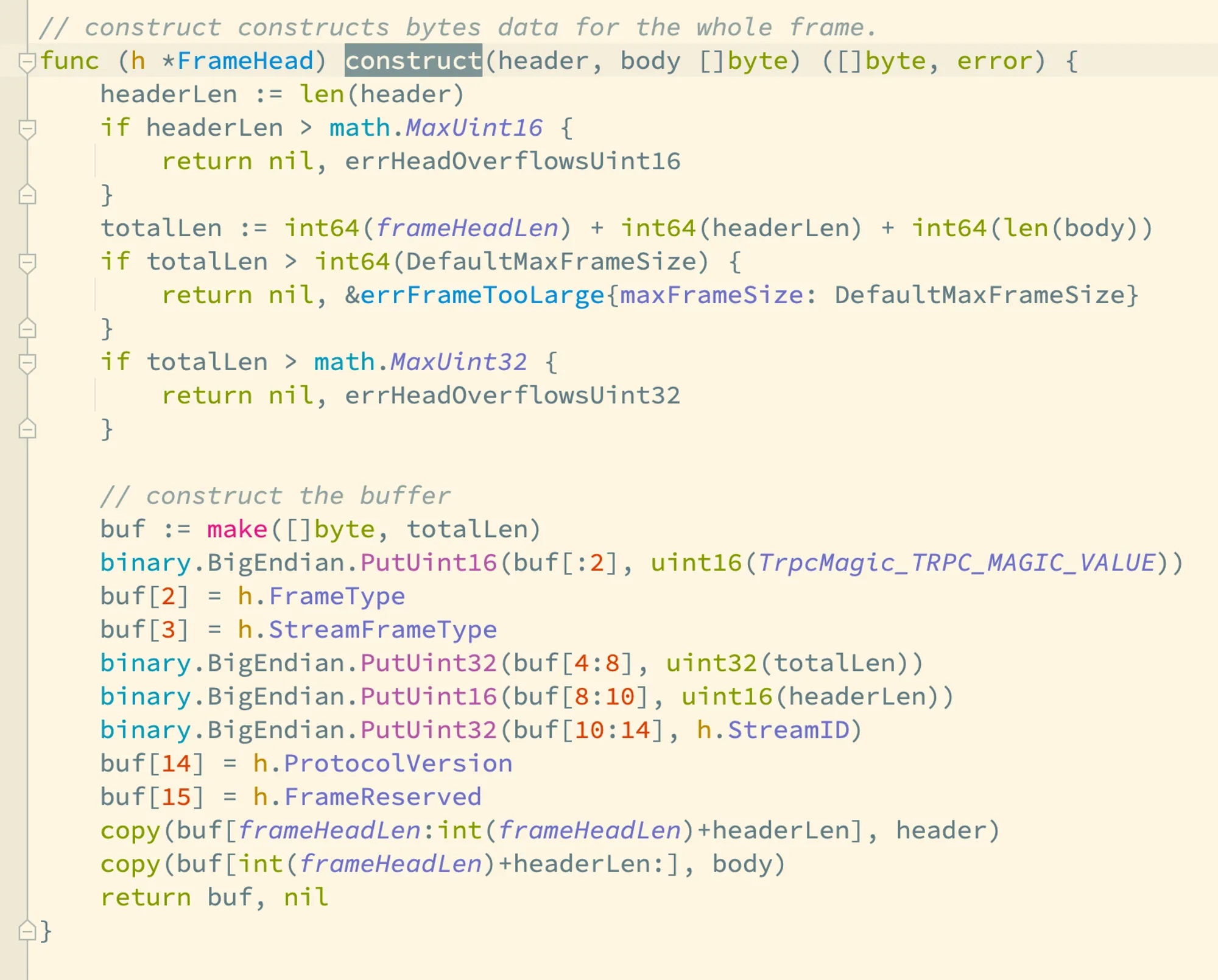
理解了这个协议,结合前面讲到的被调方解码以及反序列化的过程,我们就可以轻松知道怎么对 tRPC 帧进行分解了,进而我们就可以知道被调方是如何获得请求的头数据了:
链路透传原理
链路透传用于非功能性需求的信息传递,最常用的例子就是分布式链路追踪。在 tRPC-Go 框架中,可以使用 (*codec.Message).WithClientMetaData 在运行时中设置链路透传信息,但是在协议里,是怎么传输的呢?
我们回到讲解消息编码时的 (*codec.ClientCodec).updateReqHead 方法的逻辑:
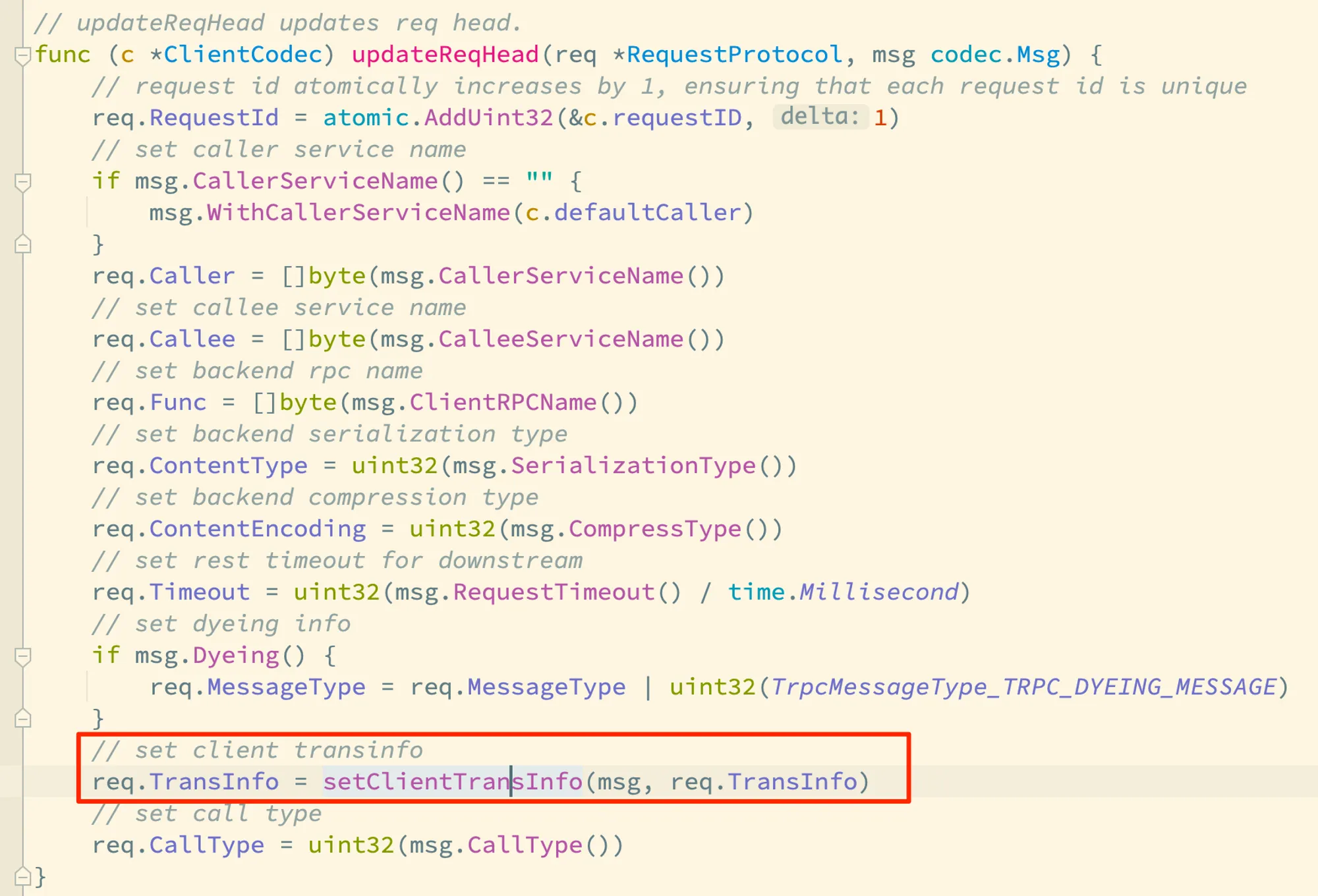
我们前面讲到,req 是报文头,这里 setClientTransInfo 将消息体结构中的 ClientMetaData 拷贝给了报文头中的 TransInfo 字段:
![]()
![]()
上面的图片展示了运行时内存中的 msg 结构化数据的字段如何和 tRPC 协议消息头中的特定字段映射,可以看到,除了链路透传信息,trpc 协议还将请求 ID 和超时控制做了标准化。
拦截器
tRPC-Go 框架的拦截器是日常开发中不得不接触的组件,也是整个框架中最有活力的部分。拦截器是一种面向切片编程思想的设计产物。通常用于一些非功能性需求的实现,比如日志打印、链路追踪、监控上报以及认证逻辑等。
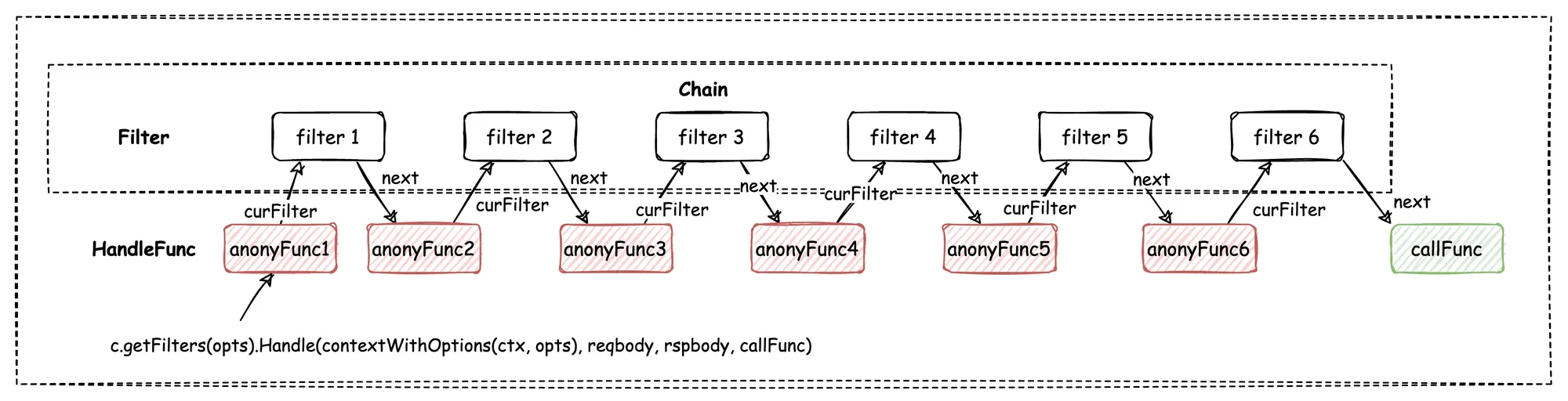
上面的图片是 tRPC-Go 框架中拦截器链的图示,callFunc 是框架内部定义的核心处理逻辑,上面的 filter 则是框架配置的多个过滤器,他们在服务启动时被注册到过滤器链中。在运行时,这些过滤器被匿名函数化,目的保持其函数签名和 callFunc 的函数签名一致,在框架中定义为 HandleFunc。带着这个理解,我们看看相关的源码,我们同样只看主调方的逻辑就好了,被调方的拦截器链实现是基本一样的:

在一次 RPC 调用中,next 参数即为我们前面讲解过的 client.callFunc 函数,它位于整个运行模型的最里层。在 Filter 的实现里,90到97行依次让拦截器链上的每个拦截器都适配成一个 ClientHandleFunc ,即前面图片中的匿名函数,并且让这个函数被其更前面的一个拦截器所引用,以此实现了将拦截器和核心的 client.callFunc 函数连接起来。事实上,这里的代码行数不多,但是因为循环引用了同一个变量,阅读起来还挺费劲的。
每个匿名函数都包装了对应的一个拦截器,同时在调用中给拦截器传递了其后一个拦截器的适配函数。
总结
tRPC-Go 是一个优秀的 RPC 框架,完整的模块思考确保了业务的适应性,加上插件机制又保证了业务的可扩展性,让 tRPC 框架成为集团层面的统一框架具备了实力。本文通过一个 RPC 调用过程从粗到细的讲解,展现了框架内部核心逻辑的实现逻辑。但是这里讲解的内容只是 tRPC-Go 框架的冰山一角,还有更多的比如指标监控、性能治理以及熔断处理等功能的内容,这些功能分布在整个 RPC 调用和响应过程的角角落落,如果你在阅读完本文后,仍然有兴趣研究 tRPC-Go 框架的实现原理,还需要自行下载阅读框架源码,而这篇文章则是给你提供了一个上手的脉络。
版权声明:本文为原创文章,转载请注明来源:《腾讯 tRPC-Go 框架核心实现源码解读 - Hackerpie》,谢绝未经允许的转载。